
Ausgeprägte Trockenheit sowie Hitzephasen führten in den vergangenen Jahren in den nordbayerischen Wäldern zu deutlichen Schäden an Laubhölzern sowie Borkenkäferkalamitäten an Fichte. Vor dem Hintergrund, dass zukünftig mit einem weiteren Temperaturanstieg und einer Zunahme von Wetterextremen gerechnet werden muss, besteht von Seiten der Forstpraxis der Wunsch nach effizienten Überwachungs- und Erfassungssystemen, um geschädigte Bäume und Waldbestände möglichst frühzeitig erkennen und präzise lokalisieren zu können. Deshalb untersuchte die LWF gemeinsam mit der Firma IABG in den Forschungsprojekten BeechSAT und IpsSAT die Einsatzmöglichkeiten von optischen Fernerkundungstechniken und KI-Methoden zur Schaderfassung.
Im Vergleich zu Feldaufnahmen ermöglichen Fernerkundungsdaten eine flächendeckende Sicht auf Waldgebiete. Durch den Blick von oben kann ein guter Überblick über den Zustand von Beständen gewonnen werden (vgl. Abbildung 1).

Abb. 1: Der Luftbildausschnitt zeigt geschädigte bzw. entlaubte Buchen im Naturwald Irtenberger Wald. Zum Vergleich eine Fotografie vom Boden mit den entsprechenden Nummern für die gleichen Baumkronen. Foto: Christoph Straub (LWF)
Forschungsprojekte BeechSAT und IpsSAT
Der Fokus der Untersuchungen im Projekt BeechSAT (2019–2020) lag auf der Entwicklung und Prüfung einer Methodik zur möglichst effizienten Detektion geschädigter, d.h. entlaubter Rotbuchen. Dafür wurden zwei Projektgebiete in Unter- und Oberfranken ausgewählt. Ab dem Jahr 2020 befasste sich dann das Projekt IpsSAT mit Möglichkeiten und Grenzen der Erfassung und Beobachtung von Borkenkäferschäden an Fichten. Dabei konzentrierten sich die Arbeiten auf die Erkennung späterer Befallsstadien, bei denen sich die Fichten bereits rotbraun oder grau verfärbt haben und somit in optischen Fernerkundungsdaten sichtbar werden. Eine Früherkennung kann damit nicht realisiert werden.
Es wurden Bilddaten mehrerer Erdbeobachtungssatelliten mit unterschiedlicher räumlicher und spektraler Auflösung verglichen. Zusätzlich erfolgte ein Vergleich mit Luftbilddaten, die mittels einer Messkamera aus einem Flugzeug aufgenommen wurden:
- Luftbilder (4 Spektralbänder)
- WorldView-3 (8 Spektralbänder)
- SkySat (4 Spektralbänder)
- PlanetScope (4 Spektralbänder)
- Sentinel-2 (10 Spektralbänder)
Abbildung 2 veranschaulicht, wie wichtig die räumliche Auflösung der Bilddaten zur Erkennung einzelner Bäume und zur Beurteilung von Kronenstrukturen ist. Zusätzlich zu den oben aufgelisteten Fernerkundungsdaten wurde hier ein sehr hochaufgelöstes Luftbild von einem unbemannten Luftfahrzeug (UAV/Drohne) hinzugefügt. In oranger Farbe wurden zwei stark geschädigte, entlaubte Buchen umrandet. Nur in den hochaufgelösten Bilddaten vom UAV und vom Flugzeug sind die Schadmerkmale "Entlaubung" und "Kronentotholz" gut erkennbar. Mit abnehmender räumlicher Auflösung wird die Beurteilung der Kronenstruktur immer schwieriger. In den PlanetScope und Sentinel-2 Daten sind einzelne Baumkronen gar nicht mehr identifizierbar.

Abb. 2: Darstellung von zwei entlaubten Buchen in Luftbildern von der Drohne (UAV) und vom Flugzeug sowie in unterschiedlichen Satellitenbilddaten. In den Klammern ist die räumliche Auflösung der Bilddaten angegeben.
Maschinelles Lernen zur Detektion geschädigter Bäume
Das Forschungsgebiet Machine Learning (ML) bzw. Maschinelles Lernen ist ein Teilbereich der Künstlichen Intelligenz. ML-Methoden werden mittlerweile für zahlreiche Anwendungen im Bereich Bildverarbeitung – beispielsweise zur Bildklassifikation oder Objekterkennung – eingesetzt und auch zunehmend zur automatisierten Auswertung von Fernerkundungsdaten genutzt.
Ein wesentliches Ziel der Projekte BeechSAT und IpsSAT war die Prüfung unterschiedlicher ML-Methoden zur automatisierten Detektion geschädigter Bäume in den oben genannten Bilddaten. Hierfür wurden Methoden des überwachten Lernens eingesetzt, d.h. das ML-Verfahren muss vor der Anwendung zuerst mit einem manuell erstellten Lerndatensatz – in der Fachliteratur oft auch als "Labels" bezeichnet – "trainiert" werden. Dabei wird dem Algorithmus beigebracht, wie vitale und wie geschädigte Bäume in den Fernerkundungsdaten aussehen. Durch Anwendung eines ausreichend trainierten Modells auf die gesamte Luftbildaufnahme oder Satellitenbildszene kann dann jedes Bildelement bzw. Pixel zu einer der beiden Kategorien vital oder geschädigt zugeordnet werden.
Klassisches Machine Learning und Deep Learning
In BeechSAT und IpsSAT wurden zwei Ansätze getestet:
- Random Forest (Breiman 2001): Als Beispiel für ein klassisches Verfahren des maschinellen Lernens wurde Random Forest zur Bildklassifikation ausgewählt. Basierend auf Trainingsbeispielen für die Zielklassen werden bei diesem Verfahren viele (unkorrelierte) Entscheidungsbäume, ein sogenanntes Ensemble, generiert. Das trainierte Random Forest Modell kann dann verwendet werden, um auf der Grundlage neuer Daten Vorhersagen zu treffen.
- U-Net (Ronneberger et al. 2015): Als Deep Learning wird ein Teilgebiet des Maschinellen Lernens bezeichnet. Dabei werden tiefe, künstliche neuronale Netze (deep neural networks) mit Lerndaten trainiert. In den vergangenen Jahren hat die Forschung zur Auswertung von Fernerkundungsdaten mit Deep-Learning-Modellen stark zugenommen. Bei der Verarbeitung von Bilddaten kommen insbesondere verschiedene Varianten des Convolutional Neural Network (CNN) zum Einsatz. Diese eignen sich in besonderem Maße, um Informationen aus Bilddaten zu extrahieren. In den Projekten BeechSAT und IpsSAT wurde dafür die U-Net-Architektur eingesetzt.
Für das Training von klassischen Verfahren des maschinellen Lernens wird üblicherweise eine gezielt ausgewählte begrenzte Anzahl von möglichst repräsentativen Pixeln oder Bildregionen für die Zielklassen verwendet. Im Vergleich dazu werden für Deep Learning Modelle – aufgrund ihrer wesentlich größeren Anzahl an lernbaren Parametern – ein Vielfaches an Trainingsdaten benötigt. Dabei werden die Trainingsdaten für ein U-Net häufig in Form von kleinen Bildausschnitten benötigt (mit einer Größe von beispielsweise 256×256 Pixel). Für jeden dieser Bildausschnitte muss eine binäre Maske generiert werden, welche die Objekte der Zielklasse (hier geschädigte Baumkronen) abgrenzt. Die Erstellung dieser Maske erforderte sowohl eine manuelle Markierung einer Vielzahl von geschädigten Bäumen als auch eine automatische Segmentierung der Baumkronen, die anschließend stellenweise erneut per Hand angepasst werden mussten. Die Anfertigung der Trainingsdaten ist somit ein zeitaufwändiger Arbeitsschritt. Um die Robustheit des Deep-Learning-Modells zu verbessern, wurde der verfügbare Trainingsdatensatz mit Techniken der Datenerweiterung (data augmentation) künstlich weiter vergrößert. Aufgrund der großen Datenmenge und der damit verbundenen rechenintensiven Lernphase werden für Deep-Learning-Modelle entsprechend leistungsstarke Computer benötigt.
Beim klassischen ML müssen für die Modellerstellung relevante Merkmale bzw. erklärende Variablen zur Trennung von geschädigten und vitalen Bäumen aus den Fernerkundungsdaten ausgewählt werden. Zusätzlich zu den originären Spektralbändern wurden dafür auch aus den Originaldaten abgeleitete Vegetationsindizes wie z. B. der Normalized Difference Vegetation Index (NDVI) verwendet. Im Gegensatz dazu sind für ein CNN-Modell die originären Spektralbänder in der Regel ausreichend, um daraus selbst Merkmale für die Trennung von geschädigten und vitalen Bäumen zu extrahieren und zu erlernen.
Welche Genauigkeiten können erzielt werden
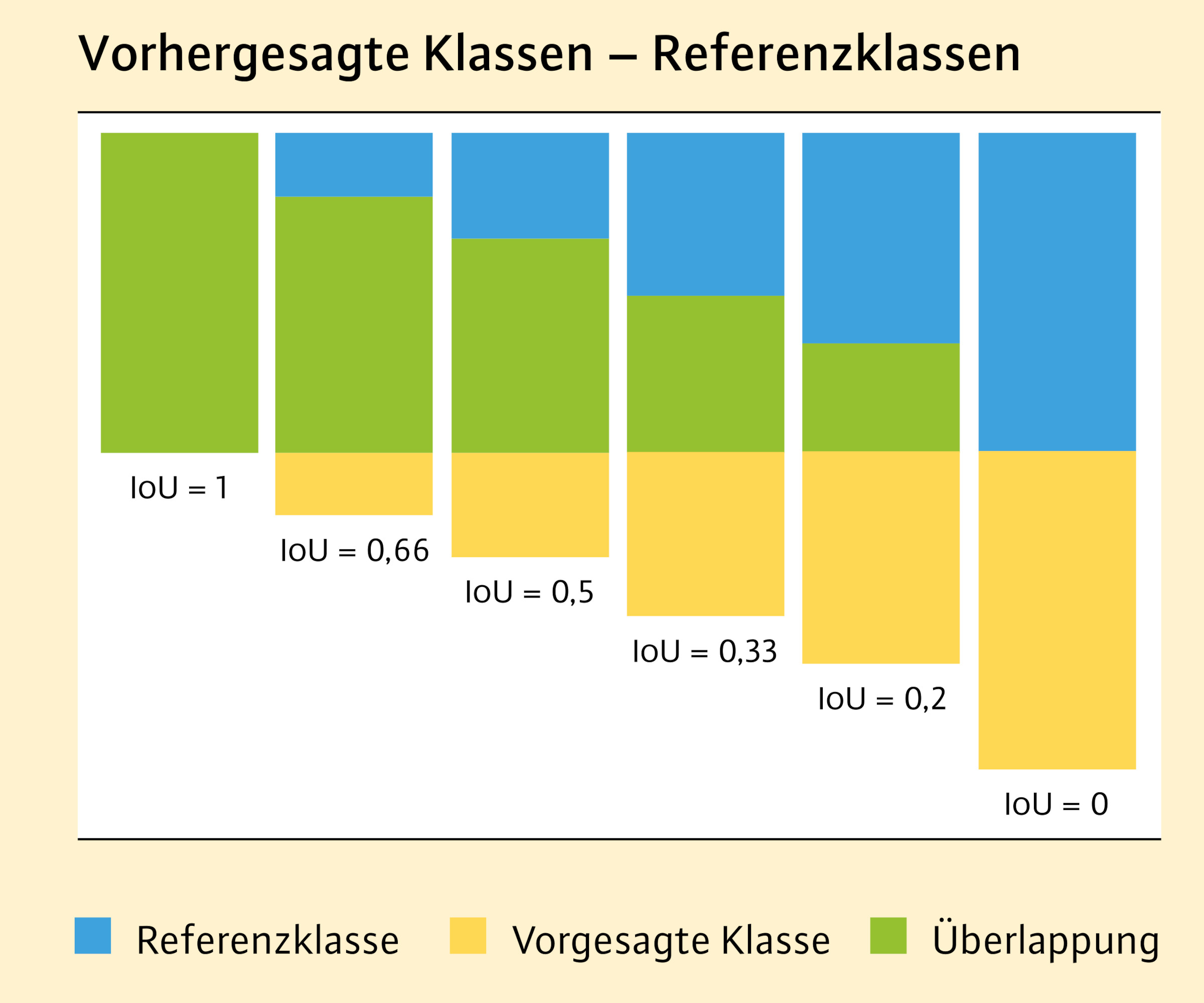
Abb. 3: Darstellung unterschiedlich stark ausgeprägter Überlappungsbereiche (grün) von einer mittels Machine Learning automatisiert vorhergesagten Klasse (gelb) und einem manuell erstellten Referenzdatensatz (blau). Als Maß für die Übereinstimmung wurde jeweils der abgeleitete Wert für die Intersection over Union (IoU) angegeben.
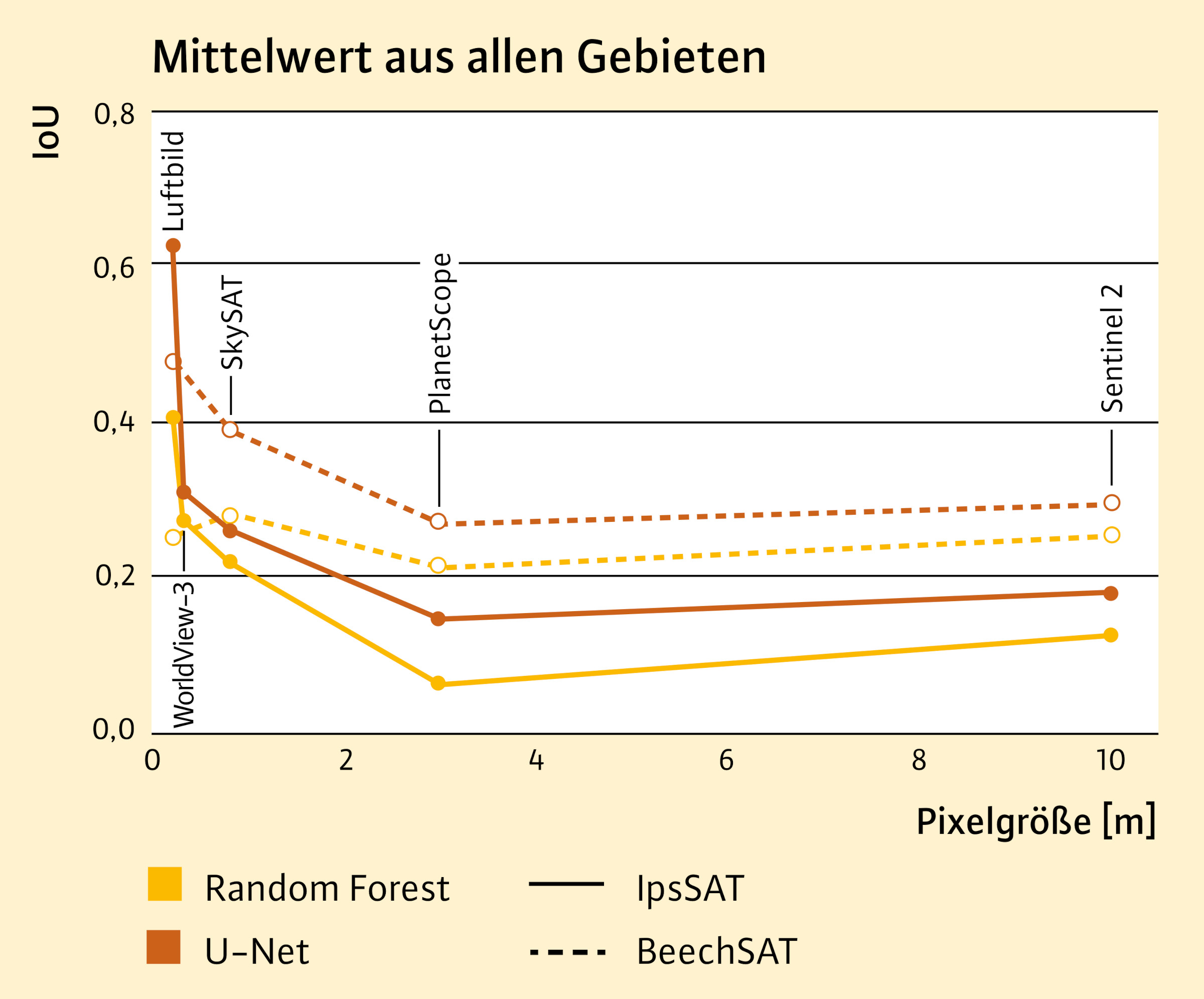
Abb. 4: Erzielte Genauigkeiten am Beispiel der Intersection over Union (IoU) getrennt für Random Forest und für das U-Net- (Deep Learning) Modell für die einzelnen Fernerkundungsdaten. Die in den Testgebieten abgeleiteten IoU-Werte wurden jeweils für das Projekt BeechSAT und IpsSAT gemittelt.
Um die Genauigkeit der fertig trainierten Modelle zur automatisierten Erfassung von geschädigten Bäumen beurteilen zu können, wurden innerhalb von jedem Untersuchungsgebiet kleine Testgebiete abgegrenzt. Die Bildinhalte in diesen Testgebieten dienten ausschließlich zu Validierungszwecken und wurden nicht für das Training der Modelle genutzt.
Für die quantitative Bewertung der Modelle wurde die sogenannte Intersection over Union (IoU) verwendet. Die IoU wird auch als Jaccard-Koeffizient bezeichnet und beschreibt die Ähnlichkeit von Mengen. Im vorliegenden Fall drückt die IoU die flächige Übereinstimmung von automatisiert erfassten geschädigten Bäumen mit einem manuell erstellten Referenzdatensatz aus. Die Übereinstimmung wird im Wertebereich zwischen 0 bis 1 ausgedrückt. Umso näher bei 1, desto besser ist die Übereinstimmung. Abbildung 3 soll die Interpretation unterschiedlicher IoU-Werte erleichtern.
In Abbildung 4 sind die berechneten IoU-Werte sowohl für Random Forest als auch für das U-Net- (Deep Learning) Modell für alle getesteten Fernerkundungsdaten getrennt für das Projekt BeechSAT und IpsSAT gezeigt. Es zeigt sich, dass mittels Deep Learning in den Testgebieten durchgängig bessere Genauigkeiten erzielt werden konnten. Der Unterschied in den IoU-Werten zwischen Random Forest und U-Net ist für die Luftbilddaten mit der höchsten räumlichen Auflösung am größten. Außerdem hat die räumliche Auflösung der Bilddaten einen wesentlichen Einfluss auf die erzielbaren Genauigkeiten. Insbesondere beim U-Net konnten mit den hochaufgelösten Fernerkundungsdaten die besten Ergebnisse erzielt werden. Wie Abbildung 2 verdeutlicht, können nur in sehr hochaufgelösten Fernerkundungsdaten die Strukturen von geschädigten und vitalen Baumkronen sichtbar gemacht werden, die ein Deep-Learning-Verfahren potenziell erlernen kann. Bei Verwendung von geringer aufgelösten Bilddaten, in denen Einzelbaummerkmale nicht mehr erkennbar sind, basiert die Differenzierung von geschädigter und vitaler Vegetation in erster Linie auf Unterschieden in den Spektralwerten. Im Vergleich zu PlanetScope haben die Sentinel-2 Bilder eine geringere räumliche Auflösung. Trotzdem konnten mit Sentinel-2 etwas bessere IoU-Werte berechnet werden, was hier auf die höhere spektrale Auflösung der Sentinel-2 Bilder zurückgeführt wird.
In Abbildung 5 ist beispielhaft ein kleiner Luftbildausschnitt vom Projekt IpsSAT mit verfärbten Fichten gezeigt. Dargestellt sind die zugehörigen automatisiert erstellten Klassifizierungen mittels des trainierten Random Forest und U-Net-Modells sowie ein manuell angefertigter Referenzdatensatz. Im Vergleich zur Random Forest Klassifizierung hat das U-Net hier kompaktere und homogenere Regionen für die Schadkategorien red-attack und gray-attack bzw. rotbraun oder grau verfärbte Fichten ausgeformt. Zudem kommen beim Einsatz des U-Net weniger ungewünschte Verwechslungen mit Hintergrundklassen wie beispielsweise Boden- und dunklen Schattenbereichen vor.

Abb. 5: Beispiel für eine Bildauswertung des Projekts IpsSAT. Dargestellt ist die automatisierte Klassifizierung von verfärbten Fichten mit den Schadkategorien red- und gray-attack mittels Random Forest und einem U-Net- (Deep Learning) Modell für einen Luftbildausschnitt.
Fazit
Bei der Anwendung von klassischen Verfahren des maschinellen Lernens wie Random Forest werden üblicherweise spezifische Modelle für eine bestimmte Situation entwickelt, d.h. die Modelle werden für ein abgegrenztes Untersuchungsgebiet oder einen einzelnen Fernerkundungsdatensatz mit möglichst homogenen Verhältnissen bezogen auf die Spektralwerte angepasst. Dabei werden möglichst repräsentative Trainingsregionen für die Zielklassen im Bild ausgewählt. Bei der Anpassung der Modelle müssen oft mehrere Aspekte wie etwa die jeweilige Beleuchtungssituation der Aufnahmen, die Phänologie zum Aufnahmezeitpunkt, die Topografie oder auch verschiedene Altersklassen im Untersuchungsgebiet berücksichtigt werden. Die direkte Übertragbarkeit von klassischen Machine-Learning-Modellen von einem Fernerkundungsdatensatz auf einen anderen ist für viele forstliche Fragestellungen ohne erneutes Training bisher kaum bis nicht möglich.
Durch den Einsatz von viel größeren Trainingsdatensätzen soll mittels Deep Learning die Übertragbarkeit von Modellen verbessert werden. In BeechSAT und IpsSAT konnten mittels Deep Learning die besten Genauigkeiten bei der Erfassung geschädigter Bäume erzielt werden. Trotzdem kann derzeit nicht davon ausgegangen werden, dass der verwendete Trainingsdatensatz ausreicht, um die erstellten Modelle ohne erneutes Training auf andere Bilddatensätze übertragen zu können. Da die Erstellung großer Trainingsdatensätze derzeit manuell über Luftbildinterpretation durchgeführt werden muss, ist dieser Arbeitsschritt sehr arbeits- und zeitintensiv und stellt momentan einen limitierenden Faktor beim praktischen Einsatz von Deep Learning dar.
Die Untersuchung zeigte, dass ein U-Net-Modell, das mit heterogenen Trainingsdaten aus unterschiedlichen Bilddatensätzen trainiert wurde, im Vergleich zu Random Forest eine zuverlässigere Schadklassifizierung ermöglichte. Deswegen müssen zukünftig die Möglichkeiten und Grenzen von Deep-Learning-Verfahren für die fernerkundliche Schaderfassung weiter analysiert werden.
Um die Ämter für Ernährung, Landwirtschaft und Forsten in Oberfranken beim Erfassen der massiven Borkenkäferschäden und den in Folge entstandenen Kahlflächen zu unterstützen, werden seit 2021 großflächige Luftbildbefliegungen von der LWF beauftragt (Straub et al. 2023). Derzeit werden diese Befliegungsdaten manuell ausgewertet. Um die Bildanalyse zukünftig effizienter zu gestalten, soll eine automatisierte Lokalisierung von verfärbten Fichten mittels einem Deep-Learning-Modell geprüft werden.
Zusammenfassung
Vor dem Hintergrund der Laubholz- und Borkenkäferschäden in Nordbayern befassten sich die Projekte BeechSAT und IpsSAT mit der automatisierten Detektion geschädigter Rotbuchen und Fichten in Luft- und Satellitenbilddaten. Zur Bildauswertung wurden sowohl klassische Verfahren des maschinellen Lernens als auch Deep Learning Modelle zur Schaderfassung erprobt. Mittels Deep Learning konnten die besten Genauigkeiten erzielt werden. Demgegenüber steht allerdings die Notwendigkeit zur Erstellung großer Lerndatensätze zum Training eines Deep Learning Modells. Die Trainingsdaten liegen momentan nicht fertig vor, sondern müssen manuell in großer Menge über Luftbildinterpretation angefertigt werden. Um einzelne Baumkronen erkennen und hinsichtlich Entlaubung und Verfärbung beurteilen zu können, werden Bilddaten mit hoher räumlicher Auflösung benötigt.


